Why Evaluate Exists
Building with generative AI requires constant iteration — yet most teams rely on subjective judgment or limited test cases to decide if prompts or model outputs are “good enough.” This slows development, hides failure modes, and leaves products exposed to costly hallucinations and drift. Evaluate was built to solve this. It provides objective, repeatable, and audit-ready scores for every input/output pair, empowering teams to measure quality, track improvements, and move faster with confidence.Key Definitions
- Guardrail Metrics: Evaluate uses the same research-backed General-Purpose Guardrail Metrics (GPMs) as Defend and Monitor — correctness, completeness, instruction adherence, context adherence, ground truth adherence, and comprehensive safety. Custom metrics are supported for SME & Enterprise plans.
- Evaluation Run: Each run is a test of a prompt + model output pair against the selected guardrail metrics. Runs can be tagged, bucketed, and grouped for comparison (e.g., Baseline, A/B Test, Regression).
- Scores & Rationales: For each metric, Evaluate provides both a numeric score and a rationale explaining why an output passed or failed. These rationales make the system interpretable and audit-ready.
- Multi-Model Consensus: Powered by our proprietary evaluation engine, outputs are scored by multiple models to avoid single-model bias. Results are aggregated with confidence weighting, ensuring accuracy and fairness.
- Run Modes: Like other DeepRails APIs, Evaluate supports Economy, Smart, Precision, and Precision Plus modes, letting teams trade off cost vs. accuracy depending on their use case.
How Evaluate Works
Evaluate follows a lightweight but powerful lifecycle designed for rapid iteration:1
Event Submission
Developers submit prompts and model outputs to the Evaluate API, either one-off or in batch, via SDKs or directly in the Console.
2
Scoring
Each completion is decomposed into units (claims) and scored across the guardrail metrics, with rationales and confidence values attached.
3
Consensus & Output
DeepRails’ multi-model consensus engine aggregates the results, normalizes confidence, and produces final audit-ready scores.
4
Visibility
Results are logged and visualized in the Console, where runs can be filtered, tagged, and compared over time to evidence prompt improvements or detect regressions.
Console Walkthrough
The Evaluate Console is purpose-built for prompt engineering and workflow optimization, giving developers immediate feedback and traceable evidence of quality.Evaluation Runs
The Evaluation Runs tab provides a real-time table of every run, including run ID, status, model, prompt, completion, and guardrail scores. Runs can be filtered by status, metric, date range, or custom tags — making it easy to organize regression tests, baselines, or A/B comparisons.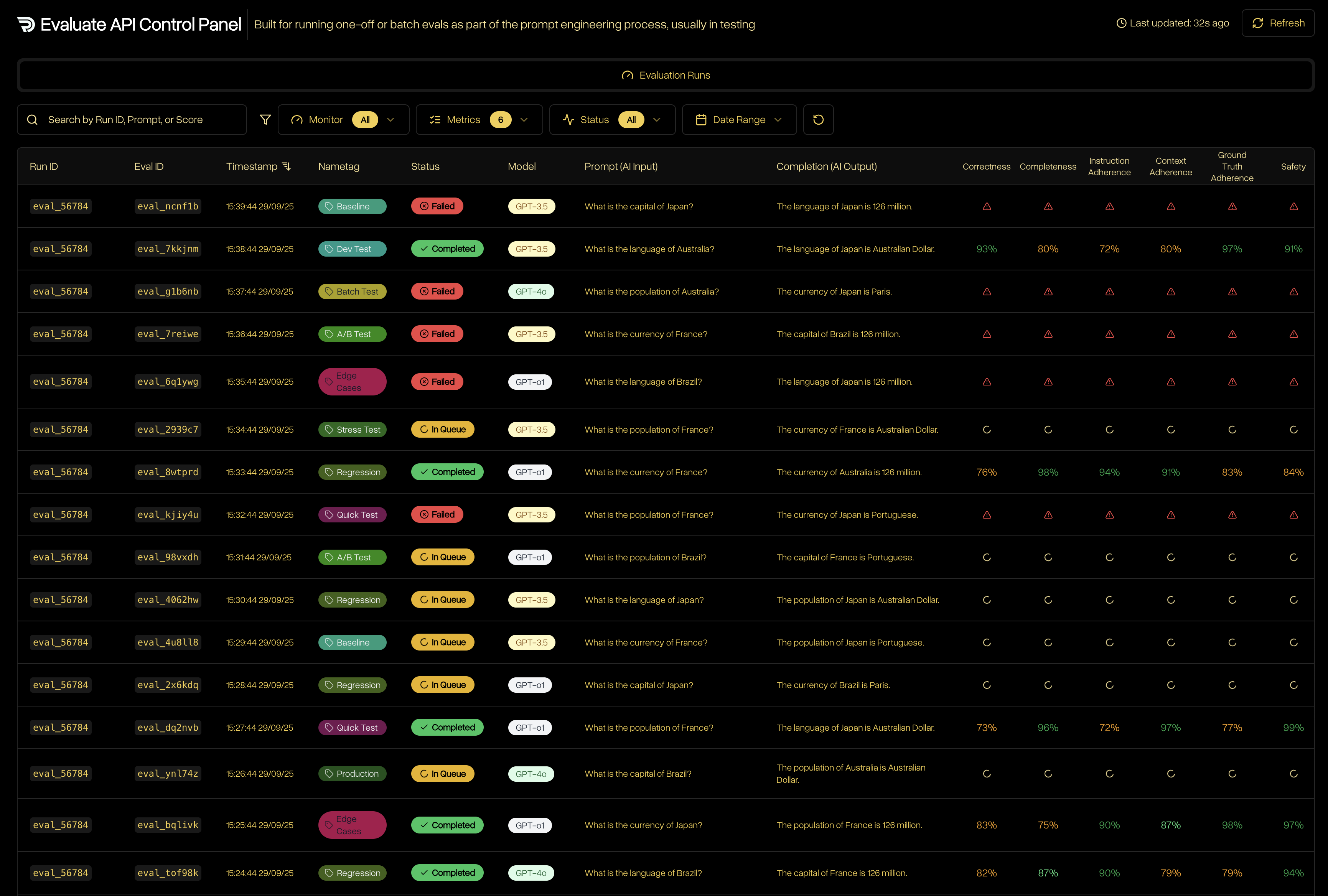
Evaluation Runs provide a clear, filterable view of every test — showing prompt, model, output, and guardrail scores across correctness, completeness, adherence, and safety.
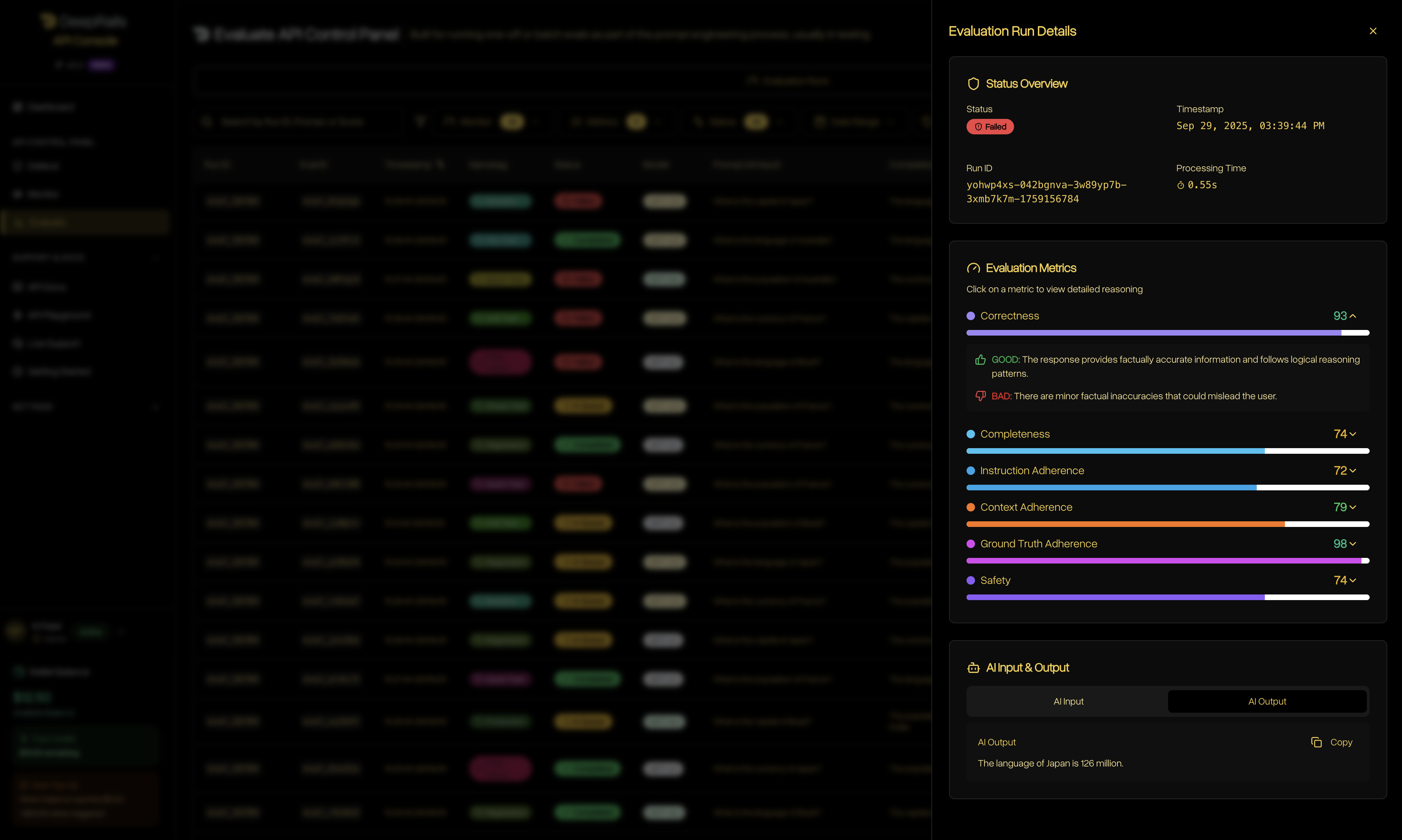
Clicking into a run reveals the full details — guardrail scores, rationales, input/output, and metadata — making every evaluation interpretable, auditable, and ready for comparison.