Understanding Guardrail Metrics
DeepRails offers a unified, comprehensive suite of Guardrail Metrics built to diagnose, debug, and improve the behavior of large language models. Each guardrail targets a specific aspect of LLM output quality, like correctness or instruction adherence. Each metric uses refined evaluation logic to deliver a continuous score and feedback that highlights both strengths and needed improvements. The table below summarizes each DeepRails Guardrail metric, how it works, and where it is most useful in your AI workflow. Because the metrics evaluate independent dimensions of the output, enabling several together gives the fullest picture.DeepRails Metric Comparison
| Name | Description | When to Use | Example Use Case |
|---|---|---|---|
| Correctness | Measures factual accuracy by evaluating whether each claim in the output is true and verifiable. | When factual integrity is critical, especially in domains like healthcare, finance, or legal. | Verifying whether a model-generated drug interaction list contains any false or fabricated claims. |
| Completeness | Assesses whether the response addresses all necessary parts of the prompt with sufficient detail and relevance. | When ensuring that all user instructions or question components are covered in the answer. | Evaluating a customer support response to check if it fully answers a multi-part troubleshooting query. |
| Instruction Adherence | Checks whether the AI followed the explicit instructions in the prompt and system directives. | When prompt compliance to components such as tone, structure, or style guidance is important. | Validating that a model-generated blog post adheres to formatting rules and brand tone instructions. |
| Context Adherence | Determines whether each factual claim is directly supported by the provided context. | When grounding responses in user-provided input or retrieved documents on top of the prompt text. | Ensuring that a RAG-based assistant only uses company documentation to answer internal HR questions. |
| Ground Truth Adherence | Measures how closely the output matches a provided correct answer (gold standard). | When evaluating model outputs against a trusted reference, such as in benchmarking or grading tasks. | Comparing QA outputs against annotated gold answers during LLM fine-tuning experiments. |
| Comprehensive Safety | Detects and categorizes safety violations across areas like PII, CBRN, hate speech, self-harm, and more. | When filtering or flagging unsafe, harmful, or policy-violating content in LLM outputs. | Auditing model-generated transcripts for PII leakage and violent content. |
How to Combine Metrics
Every Monitor and Defend workflow can include any combination of guardrail metrics. Some metrics simply are not applicable to every use case. For example, Ground Truth Adherence is critical when models must follow sources of truth beyond their inherent knowledge but unnecessary elsewhere. DeepRails evaluates each guardrail metric in parallel. This means that latency is minimized for evaluations on many metrics, but the overall evaluation will still take as long as the longest individual metric evaluation. Note that cost still increases linearly with each metric added to the evaluation, so users should avoid adding metrics that are irrelevant to the workflow they are monitoring or improving. For chatbots where cost adds up fast and user retention matters most, you might enable only Instruction Adherence and Comprehensive Safety, while complex production use cases benefit from checking Correctness, Completeness, and more.Why DeepRails Uses Granular Scoring
One of the things that sets DeepRails apart from other LLM evaluation services is the granularity of our evaluations. In any DeepRails evaluation, each selected metric receives a final score from 0% to 100%. The one exception is Comprehensive Safety, which is scored all or nothing because any safety violation causes a failure regardless of severity. This fine-grained analysis requires more complexity in the evaluation prompts. However, it yields much higher accuracy compared to competitors’ evaluations, especially for middling outputs, which are the bulk of outputs for top end Gen AI use cases. That accuracy allows users to confidently set specific hallucination thresholds in our Defend service. The difference between a 65% and an 80% threshold is meaningfully different, unlike in other evaluation products lacking granularity, so users can adjust leniency in small increments when perfecting their Defend setups.DeepRails vs. Amazon Bedrock
To validate the efficacy of our evaluations, DeepRails Correctness and Completeness evaluations were compared against Amazon Bedrock evaluations in the same two categories for sixty input/output pairs, repeated three times for each service. The results showed that DeepRails aligned much more closely with human-assigned Completeness and Correctness grades for scores between 40% and 80%. This is the range where most customers draw remediation thresholds in Defend. The comparison is shown in two charts below: one covering the 40-60% score range and another covering the 60-80% range. The differences between 50% and 70% accuracy that DeepRails surfaces can determine whether an AI system remains in production.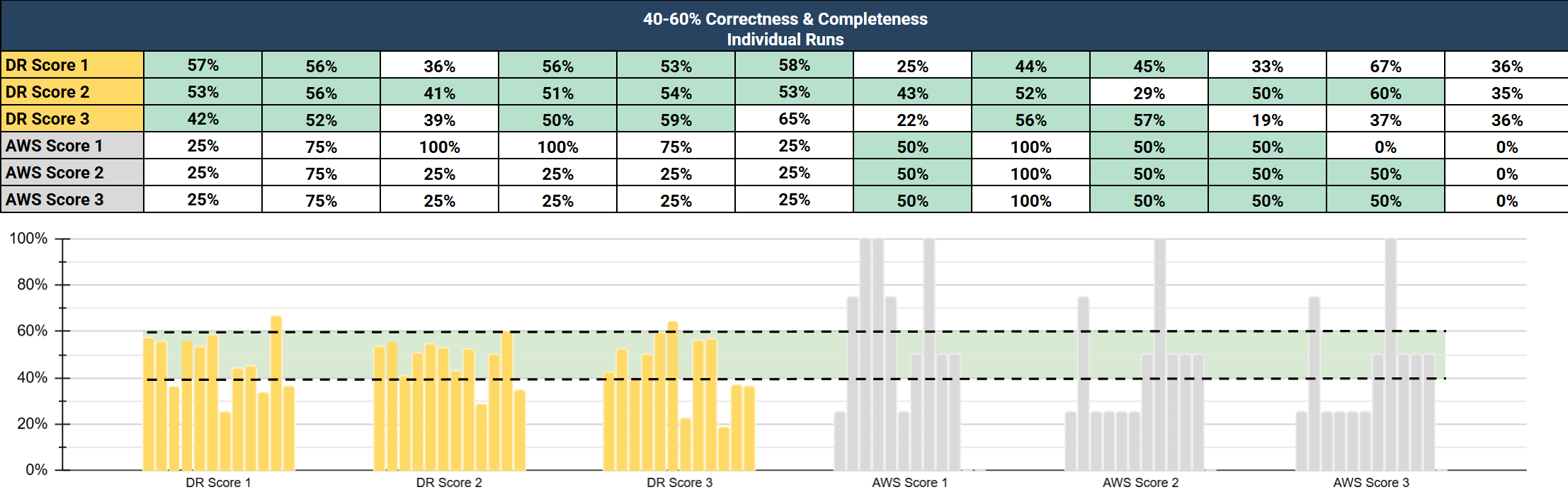
DeepRails vs. Bedrock Comparison Study: 40-60% Score Range
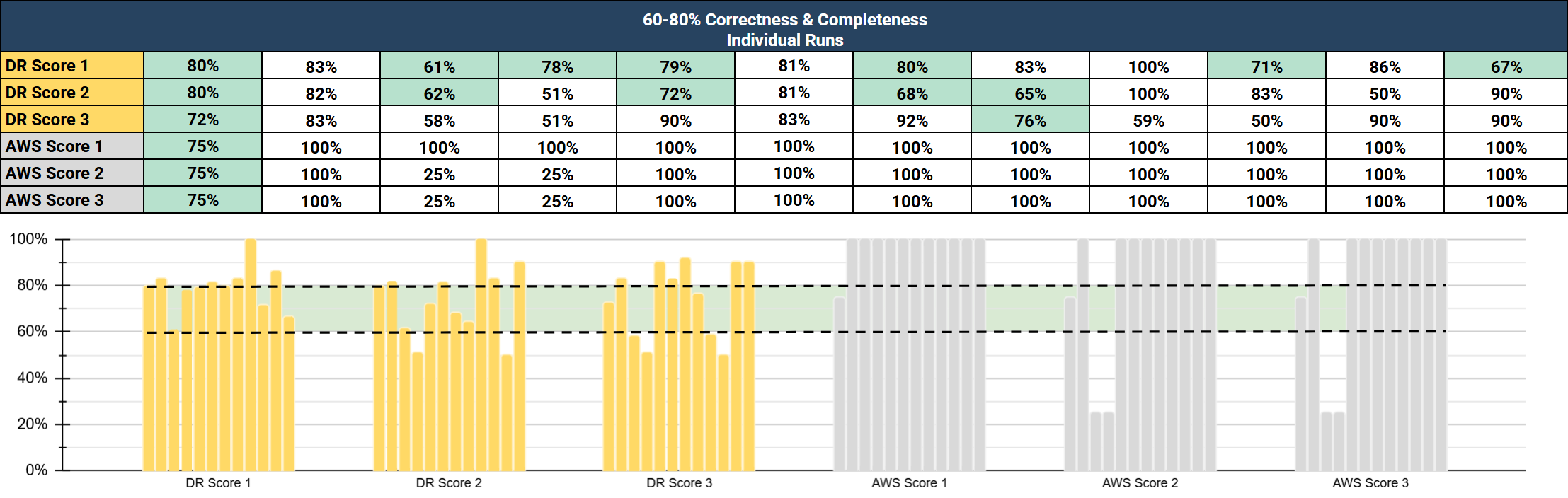
DeepRails vs. Bedrock Comparison Study: 60-80% Score Range